
Insight
The Cocktail Party Problem
A paper titled “Some experiments on Recognition of Speech, with One and with Two Ears” written by E. Colin Cherry published in May 1953, describing in detail a very interesting experiment (or rather, set of experiments) on humans. This research is based on the fact that we are able to discern and filter out unwanted sounds at will with a relative ease. The paper doesn’t only discuss the experiment with focusing on multiple audio sources at the same time, the experiment asks its’ subjects to guess the spoken language (whether it is English, German or other languages) even when they are completely focusing on different audio source(s) (I have to admit, it is a fun read). Later, this research has inspired AI experts to tackle the problem of discerning multiple audible inputs without losing information.
So, imagine you are in a large gathering in a big hall and you are talking to couple friends. Also imagine that you have other groups of people hanging around your local group and talking. Interestingly enough, you would be able to tune out all people who are talking around you and will just focus on the actual conversation going among your friends in your local group.
This is the “cocktail party problem”, sometimes you would find it under the generalized name “blind source separation”. So, how could we represent this problem mathematically and find a way to solve it?
Imagine Alice, Bob, and Carol are having 3 separate conversations while sharing the same space and talking to 3 different microphones as illustrated below:
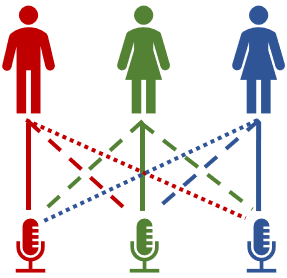
Each of these microphones will pick up/record each of their voices at a different loudness/intensity. Obviously, once we pull out the recorded sound files, will have all voices mixed. However, we can (as humans) differentiate between those voices and pick up on what has been said. Yet in order for a computer to be able to do this, the sound files have to go through several linear transformations using Independent component analysis (ICA). In this case, we sample the sound waves at certain intervals, then push them into a matrix and perform these transformations. The idea behind ICA is to find the independent variables within given data and minimizing the mutual information as much as possible. Therefore, given an example such the one above, ICA shall take the inputs of each microphone and separate the sounds of Bob, Alice and Carol with the minimal distortion.
Another example of a cocktail party kind of problem would be image analysis and decomposition. For instance, imagine that you’ve taken multiple shots of a certain image and you had a powerful glare on one of them and the other had a lesser to none glare. Using ICA, you could in fact query/separate the image from the glare. Moreover, you can extract features from images using the same technique. Furthermore, one could argue that Shazam does implement some form of ICA to capture/extract music from background sounds in order to query for the track using their music-fingerprint database.
ICA is used in unsupervised learning in AI and if you are interested in the mathematical details/model check out this paper, this demo and probably this Perl implementation. And if you are into pushing limits, here is the quantum version of the problem.
Brain soup is an independent space that gives the opportunity for employees at Infinity mesh to share their hobbies and what they are generally passionate about in the area computer science and engineering.
Trending Articles
Follow Us
Subscribe to Infinity Mesh
World-class articles, delivered weekly.