
Engineering
How to Build an Enterprise Game Platform for Millions of Players (1/3)
If you're wondering what technology to use to support millions of concurrent users with minimal hosting costs, you've come to the right place. This answer is long and not so unreachable. As an engineer, you should establish a set of technologies, skills, and most importantly, slightly different thinking models to support such longitude.
My goal for the next few articles is to share knowledge that my team and I have gained over the last two years while working on one of our projects with the primary goal of smoothly supporting millions of concurrent users.
Motivation
The main motivation for the series of articles is to help other engineers teach and learn about actor-model programming, and to quickly meet incredible performance utilizing this technology.
There aren't enough articles on this topic in the current content landscape, especially ones that discuss Microsoft Orleans, which has emerged as the framework of choice for implementing an actor programming model, which is a second motivator that prompted me to share our experience.
Two years ago, John Kattenhorn, CTO from our sister company Applicita LTD contacted me and asked if we could help a team of engineers working on an exciting project. I began analyzing various parameters such as code, architecture, and used technologies to become familiar with the project. I quickly realized that this project was different in terms of domain aspects, and it was a difference in comparison that my team and I have been recently working on, like projects where the primary goal was to solve complex business problems in various domains where they are typically labeled as enterprise software. This project was about a simple mobile game called Roshambo, also known as Rock, Paper, Scissors.
How Rock Paper Scissors works?
I believe most of you discovered this game as kids, but for some of you who are not so familiar with the rules of the game, let me explain it in the following few sentences.
Rock Paper Scissors (also known as Rochambeau, roshambo, or ro-sham-bo) is a two-person hand game in which each player forms one of three shapes with an outstretched hand at the same time. These are the shapes "rock" (closed fist), "paper" (flat hand), and "scissors" (a fist with the index finger and middle finger extended, forming a V). It is a simultaneous, zero-sum game with only two outcomes: a draw or a win for one player and a loss for the other. A player who chooses rock will beat another who chooses scissors but will lose to one who chooses paper; a play of paper will lose to a play of scissors. If both players select the same shape, the game is considered tied and is usually replayed to break the tie.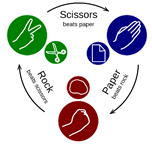
Figure 1 - Taken from https://en.wikipedia.org/wiki/File:Rock-paper-scissors.svg
After conducting the audit, we discovered that the project's condition was in good shape. Still, it did not meet the scalability requirement mainly because it is designed as a standard business application utilizing HTTP APIs as the primary communication protocol with the backend to orchestrate gameplay.
In addition, one of the difficulties in the first line was the unconventional method of scaling. For the first release, the backend was supposed to support 7K+ concurrent players. The general practice of scaling is from a smaller to a larger number of available resources, but this was not the case.
Roshambo is a competitive game in which the maximum number of players enters the game and gradually decreases throughout the game. If 100 players enter the game, and each player has only one life in each round, the number of players is cut in half if the possibility of a draw is eliminated.
Early days
Because we had a few weeks to do our research, we began focusing on specific issues in terms of gameplay very quickly. To respond to questions as soon as possible, such as:
- What should the domain look like?
- Due to the fact that we initially identified a scalability issue - we applied a microservice architecture and began asking questions about the bounding context and responsibilities of each service?
- How can we conduct large-scale gameplay testing?
- What is a cost-effective alternative to costly HTTP requests? We knew Websockets were a good choice, but we weren't certain Azure SignalR was a good fit for such a large scale.
Throughout the analysis, we created numerous process flow diagrams to demonstrate that we comprehend the entire process from beginning to end.
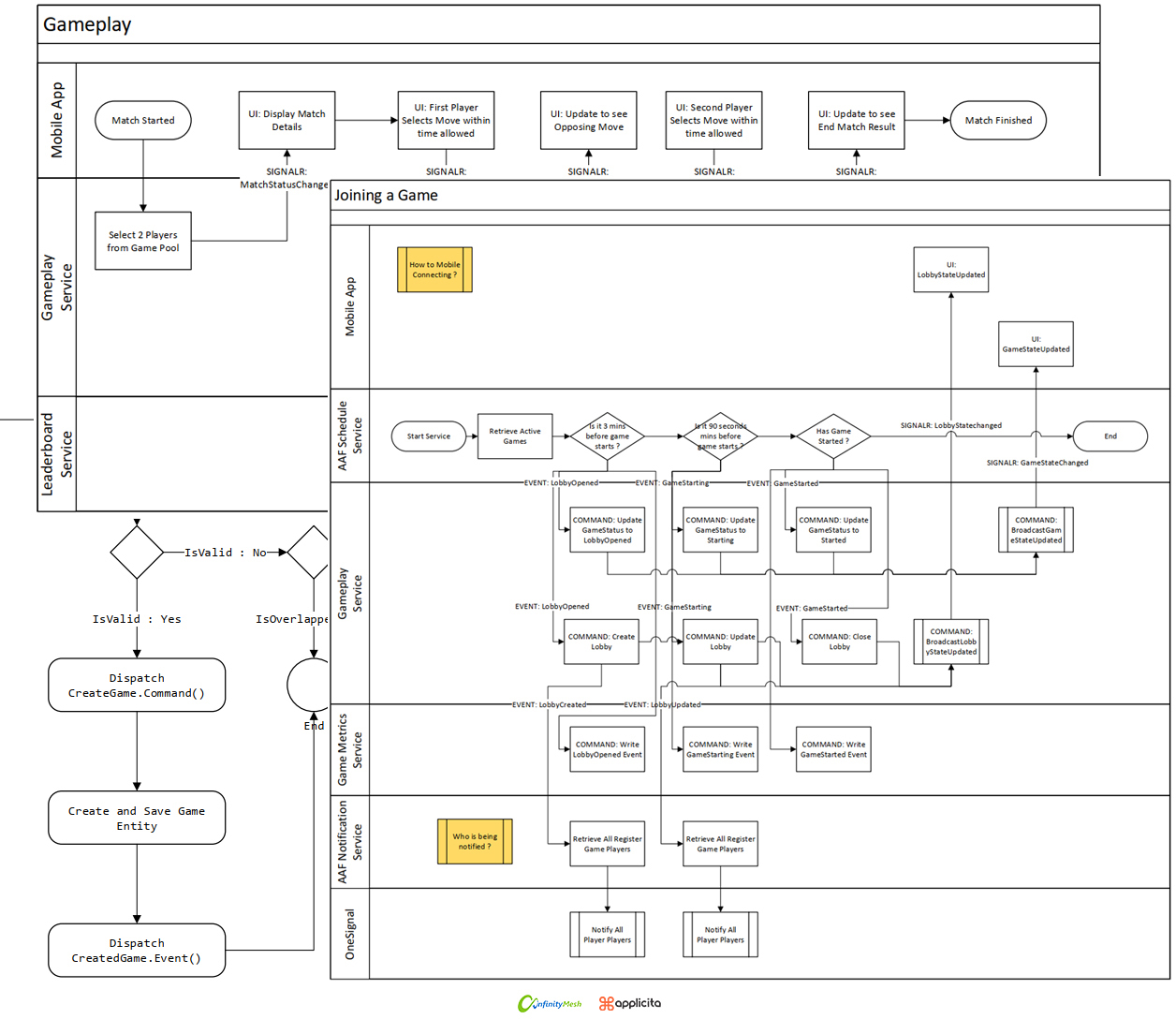
Figure 2 - Early-stage blueprints and process flows
Following the completion of the analysis, we developed an architecture prototype demonstrating how the mobile client should interact with the back-end system.
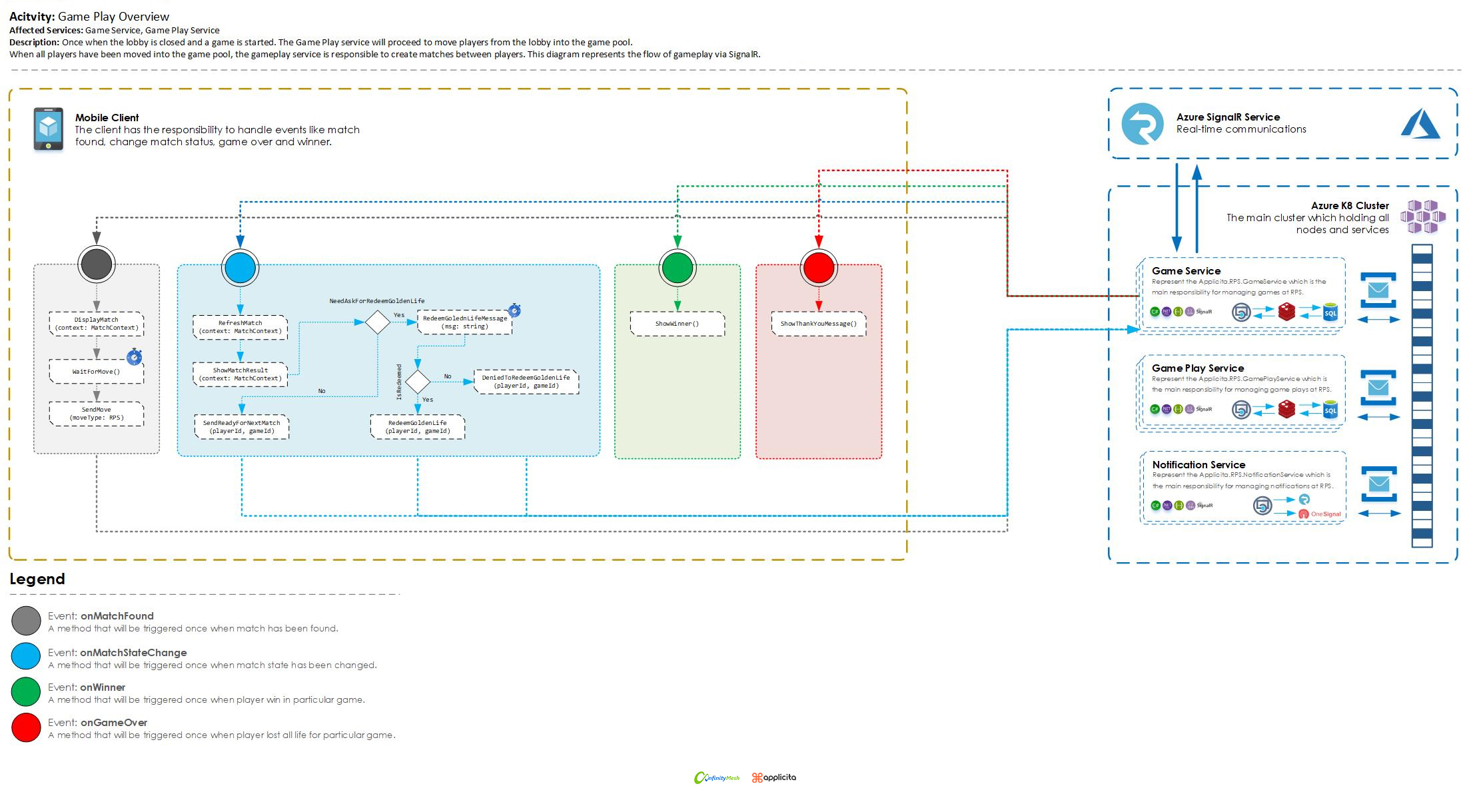
Figure 3 - The prototype of the architecture diagram
During our analysis, we also took into consideration the time frame we had to deliver the first release, which was in four months.
We have decades of experience assisting customers in improving their business processes and solving complex business problems. We have centralized our experience and best practices into blueprint projects, allowing us to accelerate the development of new projects.
The target was to meet performance that can handle about 7,000 concurrent players for the first release – we recognized that our pervasive architecture based on a microservice strategy would be an excellent fit because we can create independently deployable services and give teams autonomy to accelerate the project and focus on solving concrete domain problems.
Forming technologies and strategies
I'll go over the technologies we used, how the services communicate with one another, and what we used for primary storage in the following sections. But, before I get into the technicalities, I must say that we were ecstatic when we could reduce the entire gameplay to just four signals available to the mobile client, as demonstrated by our prototype. Furthermore, we no longer had many expensive HTTP requests, and the entire story was reduced to Microsoft Azure SignalR, which used WebSocket behind the scenes.
Microsoft Azure Kubernetes was used to orchestrate services across the cluster. As part of our blueprint project, we formed base ARM templates that required minor tweaks with newly added services, most of which are related to solving game domain problems.
Since we formed best practices in terms of writing code as part of the blueprint project, alongside microservice architecture, we have also used CQRS as a kind of local architecture across services, which allowed us to start writing isolated handlers to divide functionalities into small testable pieces. Since we had a short time window for the first release, this helped a lot to recognize small bugs before we pushed out versions to QA.
We used various storage types of SQL and NoSql for data storage, based primarily on the nature of the data. Still, the primary storage for saving data such as players, games, moves, matches, and so on was stored in various databases at Microsoft Azure SQL Server. To achieve a fast read, we had utilized Microsoft Azure Redis Cache. For data which served to analytics, we had stored asynchrony into table storage. We had chosen table storage especially because of price, and it's quite handy to use it later on for data since engineers.
We were certain that we had to take telemetry in the system seriously. We started putting a lot of effort into telemetry because we had a lot of dependencies that could affect performance. As a result, telemetry takes the status of first-class citizens in our system. The choice of Microsoft Azure Application Insight was a kind of natural selection, where the second argument is that Microsoft Azure provides the majority of the dependencies in the form of services. As a matter of fact, the integration part was only concerned with tweaking configuration. On the other hand, due to the nature of microservice architecture, where event-drive was the primary approach, we had to implement a correlation pattern in order to gracefully track activities and understand which service or dependency is causing a bottleneck. The following figures represent a portion of many benefits that we considered telemetry as a significant factor. As a result, we were able to debug and resolve the performance issues quickly. If you look at the images below, you can see how easy it is to understand where the source of the problems is.
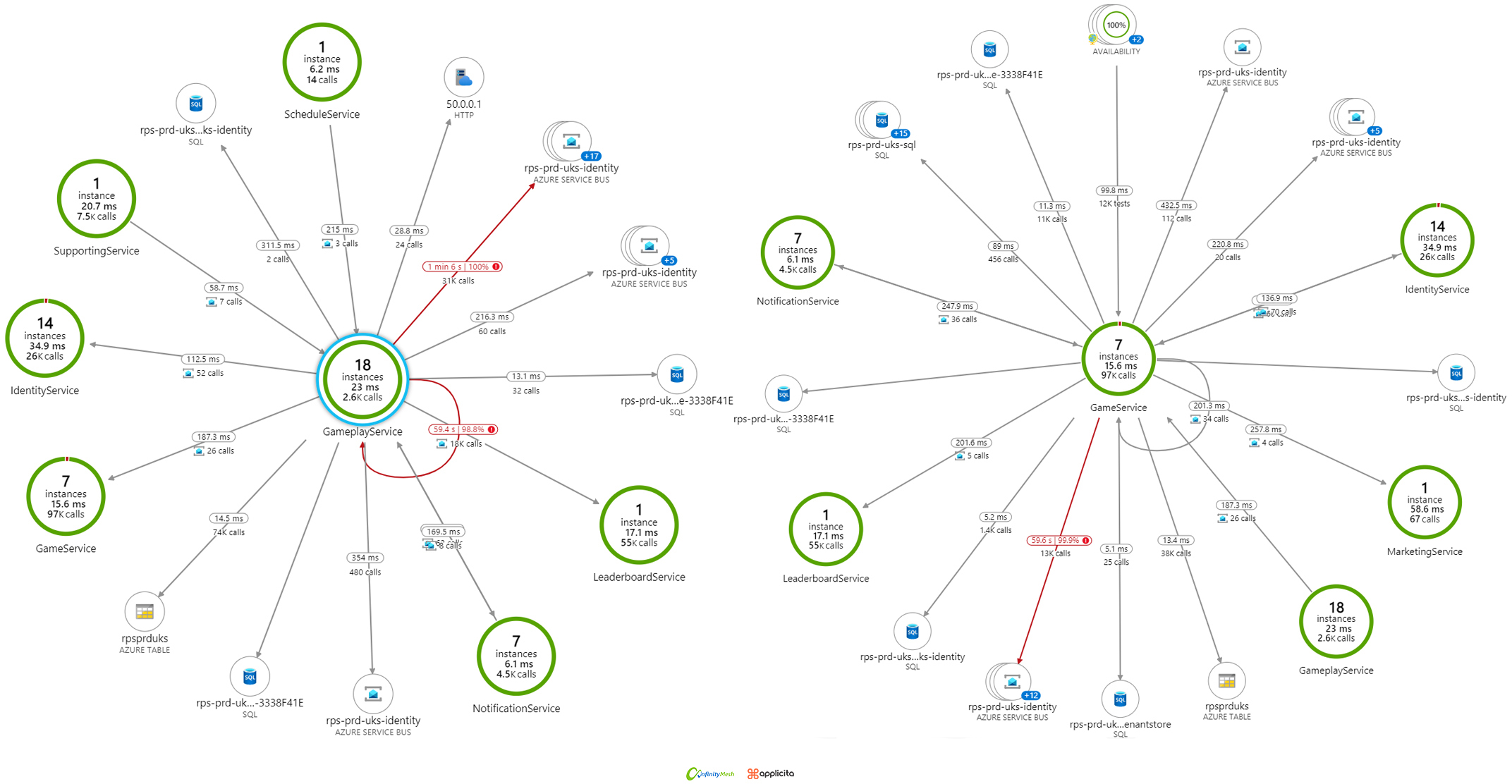
Figure 4 - Mesh telemetry representation across services
![]()
Figure 5 - Activity tracking dependencies and services
Forming methods and instruments for performance measurement
Roshambo, as a game, is simple to create in terms of business requirements. However, the main issue here is preparing the playground to put pressure on the system and measure performance. In general, we have not found out-of-the-box tools in the gaming industry that allow us to set up the game, number of players, and define parameters such as player behaviors and so on. We were fortunate to consult with pioneers in the gaming industry, such as Electronic Arts and Microsoft Playfab. We raised the issue of finding testing tools during one of our meetings, and were told that due to complexity, such tools did not exist in the capacity we were looking for and that we would have to build our own.
Fortunately, we did not spend too much time developing such a tool. Essentially, we had a mobile client app built in Unity, and we wrapped four signals required to play the game. As a result, we had a simple console application built on top of.NET Core 3.1 (the most recent version at the time). Because we needed to establish 7,000 connections to simulate concurrent players due to OS and available socket limitations, we had to compress the application into a Docker container that exposed parameters such as the number of players, behaviors, time spent in the lobby, etc.
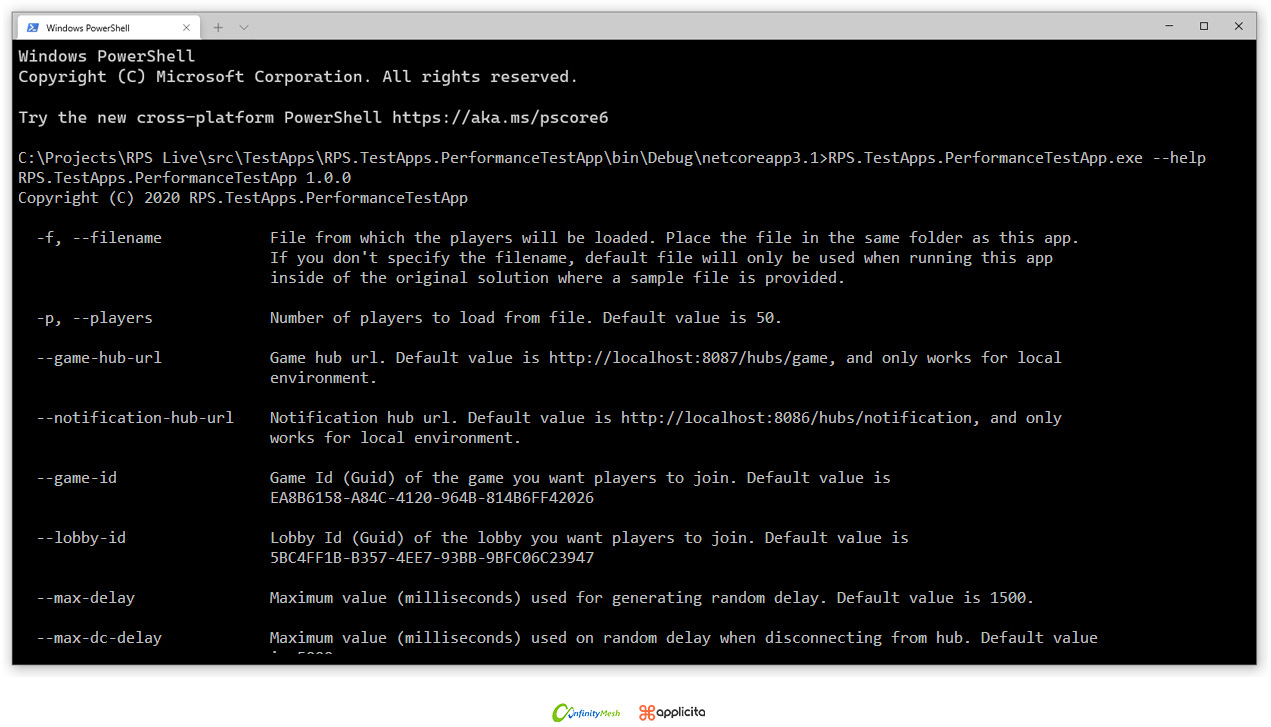
Figure 6 - Available commands at performance test application
Since we need to predict players behavior as accurately as possible, we put a mechanism to avoid a situation where all players act simultaneously; instead, we have a random delay between actions to simulate a real-world situation scenario better.
Random delay ramp-up occurs whenever players join or leave the game. The following parameters can better explain the random delay:
- Minimum delay - minimum value that can be produced when generating a random value.
- Maximum delay - maximum value that can be produced when generating a random value.
- Step - random values are gradually increased from minimum towards maximum value in steps.
To understand these properties properly let’s use an example console app setting where we want to:
- Connect 500 players to a game.
- Using a random ramp-up delay ranging from 100 to 500 milliseconds.
- With 100 millisecond steps.
--players 500 --min-delay 100 --max-delay 500 --step 100
Since the step value is 100, it means that delay range from 100-500 gets divided into 4 sub-ranges: 100-200, 200-300, 300-400 and 400-500, and groups of players will be connecting to hub with random delay values belonging to one of these 4 sub-ranges.
Ramp-up formula is used when calculating random values, so random values will increase gradually with least players connecting after 100-200 milliseconds delay, and most players connecting after 400-500 ms delay. The following graph is a visual representation (simplification) of these settings.
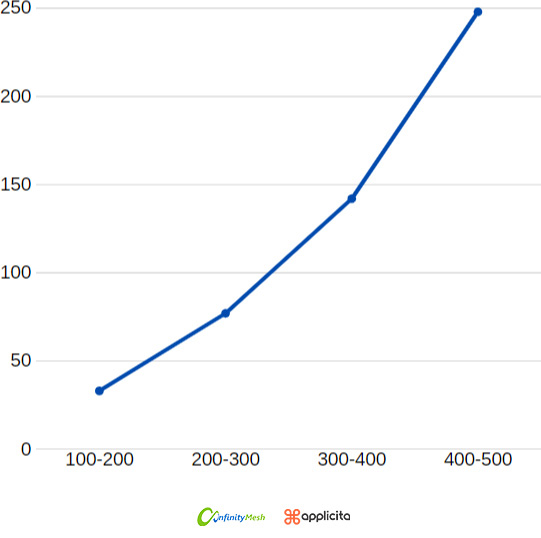
Figure 7 - A smaller step value produces a more gradual ramp-up curve, whereas a larger step value produces a choppy or broken-up curve, as shown in this example
We are looking for the following measurement parameters:
- Response time signal for resolving matches.
- Time for a match factory/finding a new match.
Both parameters are essential and should be less than one second in 95% of cases - this was our gameplay performance goal. We established a baseline of 1,000 players in a short period of time. After that, we quickly got results proving that we can run 7,000 players, which gave us the go-ahead to put release 1.0 into production.
Zero day
After soft lunch (production), we ran the first public game, which was only open to people from the United Kingdom. We had 250 real players in the first game, and everything went smoothly. The winner received a 25£ prize, while the consolation prize was 10£. The marketing team launched aggressive campaigns, and the game grew in popularity, and we soon reached 1000 concurrent players. The marketing team decided to increase the prize to 1000£ for the winner. As a result, in less than a month, we had 5000 concurrent players.
The QA and Performance teams began testing the current system with 10,000+ concurrent results, but we began to see unexpected results in our telemetry reports. We discovered that the game is gaining far more traction than we had anticipated. We were unable to achieve the same performance for >= '0 000 concurrent players as we had for >= 7 000 with the current design, prompting us to consider redesigning some of the services at the heart of our system.
In the next article, I plan to explain where we ran into problems and discover that the actor pattern would help us with scaling and getting performance up to 100 000 concurrent players. Before I publish the next article, I'd like to hear your thoughts on where the problem was based on the architecture described above, and if you had a similar experience, please let me know in the comments below.

Trending Articles
Follow Us
Subscribe to Infinity Mesh
World-class articles, delivered weekly.